简体中文
繁體中文
English
Pусский
日本語
ภาษาไทย
Tiếng Việt
Bahasa Indonesia
Español
हिन्दी
Filippiiniläinen
Français
Deutsch
Português
Türkçe
한국어
العربية




AI半導体の王者・NVIDIAを襲うインテル、AMD、グーグル包囲網 ── それでもNVIDIAが強い理由
概要:半導体メーカーNVIDIAはAIの学習向け半導体で世界トップの座にある。その同社の直近のイベントは、例年になく「地味」なものだった。その背景では熾烈な「追撃」がはじまっている。

Shutterstock
半導体メーカーのNVIDIA(エヌビディア)は3月17〜21日、テクノロジーイベント「GPU Technology Conference 2019(GTC 19)」を、アメリカ・サンノゼで開催した。
GTCは2008年に開催された「NVISION」というイベントが初回で、元々はコンピューターグラフィックスをテーマに始まった。その後、NVIDIAが「CUDA」(クーダ)と呼ばれるGPUを利用した汎用コンピューティング(GPUコンピューティング)のソフトウェア開発プラットフォームに注力するに従い、内容をそちらにシフト。近年はGPU+CUDAを利用したAI向けのカンファレンスという位置づけに変容している。
GTC 19の「地味な発表」には理由がある

GTC 19で講演するNVIDIA CEO ジェンスン・フアン氏。
ここ数年のGTCは、NVIDIAのコアビジネスの1つに成長しつつある「AI向けの半導体のソリューション」を発表する場として注目されてきた。
2017年は「Tesla V100」という最新GPUとそれを8基搭載したGPUサーバーアプライアンスの「DGX-1」を発表。2018年はこれを強化し、Tesla V100を16基搭載できるGPUサーバーの「DGX-2」を発表した。
いずれも、昨今注目が集まるディープラーニングを利用したAIを実現するための「学習」の高速な実行に必要なため、AI開発者から拍手を持って受け入れられたプロダクトだ。

NVIDIAが発表したエンタープライズ向けGPUサーバー。
では、2019年はどうだったのか。実は率直に言って、2019年にNVIDIAが発表したハードウェア関連の話題は例年ほど話題を呼ぶモノではなかった。
その代わりNVIDIAは今回、ソフトウェア開発環境の話題を多く取り上げた。
とくに、従来はcuDNNなどバラバラのブランド名で呼ばれてきたCUDA向けのソフトウェア開発キットに、新しいブランド名「CUDA-X」が与えられた。AI向けには「CUDA-X AI」で呼ばれることなどが明らかにされ、全種のエンタープライズ向けGPU搭載サーバーにあらかじめインストールして提供されるという。
AI学習向けハードの世界でNVIDIAにも「競合」が現れた

インテルが発表した第2世代Xeon Scalable Processors。
このようにCUDAやCUDA-XをNVIDIAがアピールする背景には、同社の強みだったAI/ディープラーニングの世界に、より強力な競合が現われたという背景がある。かつ、競合の追い上げはかつてないほどに急だ。
データセンターの世界王者であるインテルもその例外ではない。ただし、インテルはAIに利用されている半導体という意味では、決して負け組ではない。
というのも、データセンターにおけるAIの実現に使われているマシンラーニング/ディープラーニングの手法のうち、「推論」というプロセスのほとんどはインテルの「Xeon」プロセッサーで行なわれているからだ。

「学習」と「推論」の処理の違い。ビッグデータでAIを「賢く教育する」のが学習。そのAIを使って、モノの判別などの処理をさせるのが「推論」だ。自動運転はまさに「推論」処理にあたる。
Business Insider Japanデータセンターのマシンラーニング/ディープラーニングベースのAIは、GPUで学習され、その後CPUで推論してサービスとして提供されるのが一般的だ。「学習」とはAIを鍛えるプロセスで、これには膨大な処理能力が必要になるため、大量のGPUで並列的に処理していくのが圧倒的に理にかなっている。
それに対して、画像認識や音声認識などの具体的な処理になる「推論」では、よりプログラム的な柔軟性が求められる。また、学習ほどは処理能力が必要ないため、CPUで行なわれるのが一般的だ。
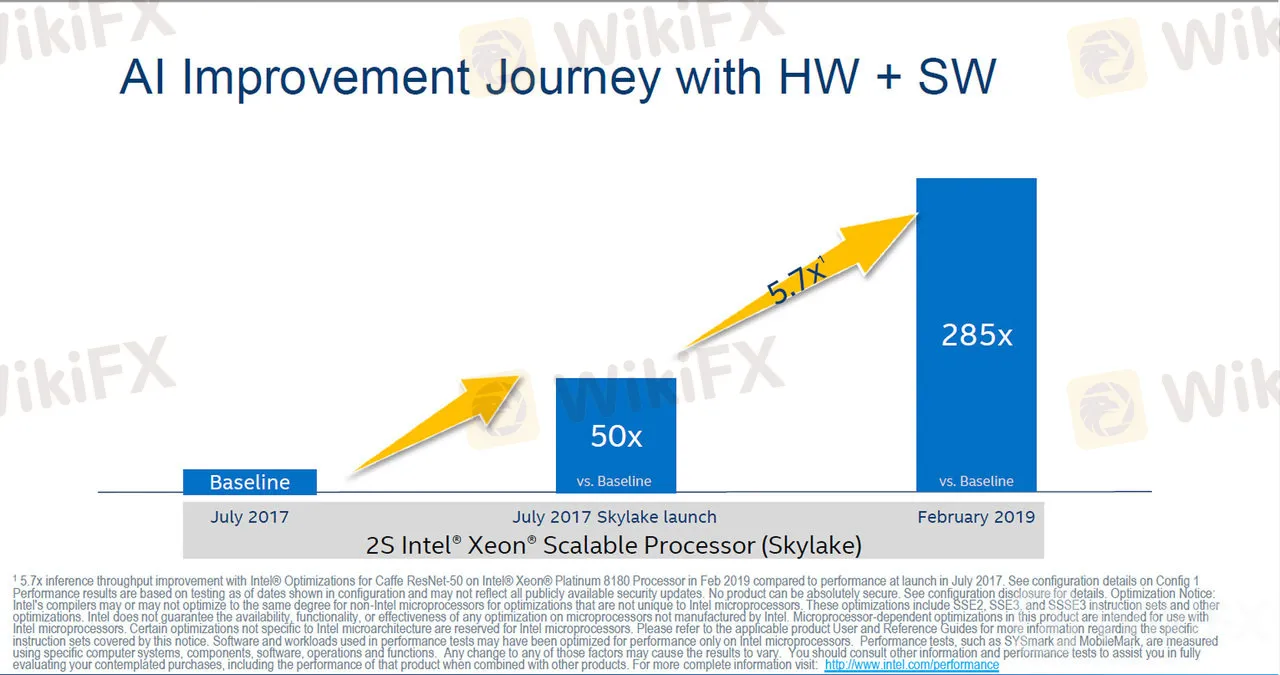
初代Xeon SPの発表時に比較して、推論性能がソフトウェアの最適化なども含めて285倍になっている。
出典:インテル
インテルは4月2日(米国時間)にそのXeonプロセッサーの最新製品となる第2世代Xeon Scalable Processors(以下、第2世代Xeon SP)を発表した。第2世代Xeon SPは新しく2つのダイを1チップに統合した製品を追加、1チップで56個のCPUコアを実現可能にしている。
また、ソフトウェア開発キットなどを改良していくことで、インテルは推論時の性能を大幅に向上させている。第2世代Xeon SPでは、従来製品のXeon SPと比較して推論時の性能が285倍になっているとアピールしている。
NVIDIAのAI「学習」の牙城に挑み始めた巨人インテル

Shutterstock

PCI Expressカード形状のIntel Nervana NNP L-1000。

Intel Nervana NNP-L1000のモジュール版(表)。

Intel Nervana NNP L-1000のモジュール版(裏)。
そのインテルは、NVIDIAの強みである学習へも踏み込もうとしている。インテルは2018年、ディープラーニングの学習専用アクセラレータの実物を公開した。これは、「Lake Crest」のコードネームで開発され、2018年に「Intel Nervana NNP L-1000」の型番で発表したものだ。
Intel Nervana NNP L-1000は、最初から「ディープラーニングの学習だけに特化」して設計されている。そのため、GPUに比較してより少ない電力でより高速に学習することができる(少ない電力で動くことは、一般に同じ電気代でより高い成果をあげられ、集積密度もあげられる可能性を高める)。
現在、インテルはこのNervana NNP L-1000について、Facebookなどのソフトウェアパートナーと大規模なベータテストを行っており、2019年末までにその製品版となる「Spring Crest」を出荷する計画だ。
さらに、インテルは2020年に単体型GPUを出荷する計画を持っている。インテルが単体のGPUを出荷するのはおよそ20年ぶりのことだ(あくまで予定だが)。
「Xe」の開発コードネームで知られる同製品は、AMDでGPUチームを率いていたラジャ・コドリ氏が率いるチームにより開発され、ディープラーニングの学習からPCゲームまで、汎用性高く使える製品と計画されている。
インテルとしては、「GPUのXe」と「アクセラレータのSpring Crest」という2本立てで、NVIDIAの牙城である学習分野で対抗する、そういう戦略だ。

インテルの上席副社長兼Intelアーキテクチャ/グラフィックスソリューション事業本部長兼エッジコンピューティングソリューション主任アーキテクト ラジャ・コドリ氏。コドリ氏が講演する後ろにはインテルの創業者である故ロバート・ノイス氏の遺影が……。
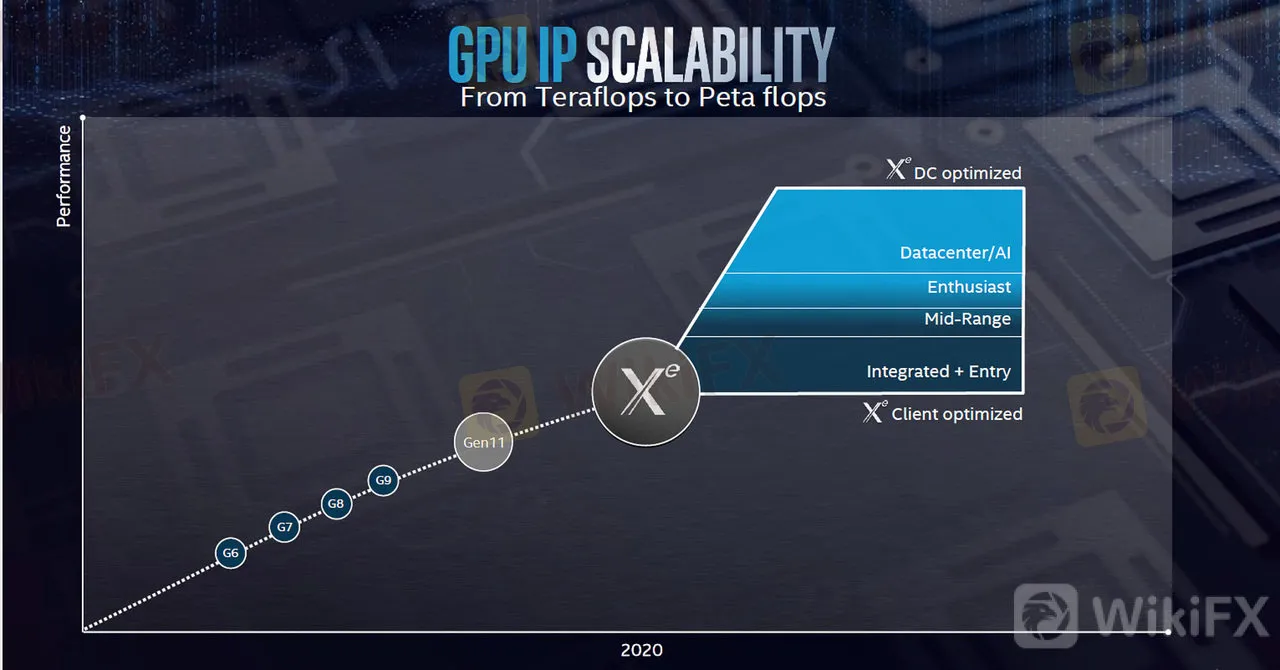
インテルが2020年に投入する予定のXeはデータセンターからPC用GPU、CPU統合までカバーする。
出典:インテル
AMDもNVIDIA対抗のAIソリューションを投入
AMDも同社の強みであるGPUの「Radeon」を利用した学習向けソリューションを提供していく。これまで同社の弱みは、NVIDIAのようにソフトウェア開発環境が整っていないことだった。
しかし、2018年にAMDがリリースしたRadeon Open Ecosystem(ROCm)は、グーグルが開発するAI/機械学習のフレームワーク「TensorFlow」への最適化ツールなどを含み、NVIDIAのCUDA向けのソフトウェアをAMD向けに変換するツールなどと合わせて提供される。
これまでAMDのGPUがディープラーニングの学習用途に使われてこなかった理由が、開発環境にあっただけに、そこを充実させることでNVIDIAとの差を縮めていく戦略だ。

2018年のGoogle NEXTでグーグルが展示した第3世代TPU。
AIジャイアント・グーグルもハード開発を進める

Shutterstock
ソフトウェア業界の巨人であるグーグルはTPU(Tensor Processing Unit)に取り組んでいる。 TPUはインテルのNervanaなどと同じようにニューラルネットの処理に特化したアクセラレータで、第1世代は推論に特化してきた。それが、第2世代と現行の第3世代では、学習にも利用できるようになった。
グーグルの強みは、TensorFlowというトップシェアのディープラーニング向けのフレームワークを持っていることだ。
もっともグーグルの場合は、NVIDIAに競合したいというよりは、自社のGoogle Cloud Platform(GCP)など、「自社のパブリッククラウドサービス向けに演算性能を上げる」というニーズを満たしたい側面が強い。実際GCPでは、NVIDIAのGPUもクラウドサービスとして提供している。
その意味ではビジネス的に競合しているかと言えば直接的にはそうではないが、GPUも同じように学習のアクセラレータとして使われている現状を鑑みれば、大きな意味では競合していると言える。
NVIDIAの「AI学習の王者」の座はこの先どうなるか

Shutterstock
このように、インテルやAMD、そしてグーグルのTPUといった新しい選択肢が登場しつつあるディープラーニングの学習向けコンピューティングソリューション。それらはNVIDIAのGPUにとって変わることができるのだろうか? 長期的には「イエス」であり、短期的には「ノー」だ。
長期的にNVIDIAに取って代わる可能性が高い理由
長期的に「イエス」と言えるのは、どちらがディープラーニングの学習を処理するのに有利かと言えば、そもそもディープラーニング学習に専用設計されているNervanaのような製品だと考えられるからだ。
現在のデータセンターは、電気容量やスペースなどに制限があり、同じアーキテクチャで性能を上げるにはプロセスルール(内部設計)を微細化(小型化、精緻化)していくしかない。
半導体業界では有名な「ムーアの法則」(18カ月で集積率が2倍になるという法則)が知られるが、すでにこの論理は行き詰まりを見せており、進化速度はスローダウンしていると見る関係者が多い。
であれば、新たな設計(アーキテクチャ)で、より効率よくディープラーニングの処理ができるNervanaのような専用アーキテクチャが、長い目で見れば有利なのは明白だ。
一方、短期的にはNVIDIAは変わらず強い
だが、短期的に「ノー」なのは、ソフトウェアの「下位互換性」という縛りを抜け出すのにはなかなか時間がかかるからだ。
NVIDIAの強みは、すでに多くのデータサイエンティストやプログラマが、同社のCUDAやCUDAを利用する多数のSDK(cuDNNなど)を利用してプログラムコードを書いており、文字通りプログラムがNVIDIAのGPUに最適化されている現状になっている。
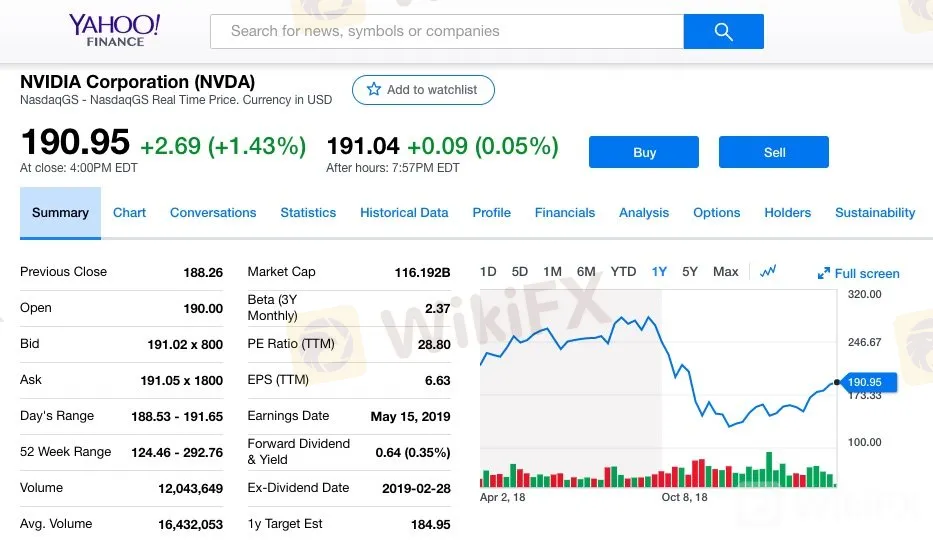
NVIDIAの直近12カ月の株価推移。4月5日時点で190.95ドルとなっている。
Yahoo!FINANCE
2018年、筆者があるソフトウェアベンダーのCEOと雑談しているときにこんな話を聞いた。
コンピューターの「命令セット」の話題になったときに「パソコン時代にはx86の命令セットが王者だった、モバイル時代にはArmの命令セットが王者になった。すでに突入しつつあるAI時代のそれは、命令セットではないがNVIDIAのCUDAになりつつある」とそのCEOは指摘したのである。
まさにこれこそが今のNVIDIAのポジションを端的に示しており、そして短期的にはNVIDIAの強さが揺らがない最大の理由だ。
その先はどうなるか? すでに述べたとおり、長期的に見ればインテルやグーグルのTPUのような新しいアーキテクチャが有利だ。ただし、そのためにはどれだけソフトウェア開発環境を整え、AIのプログラムをつくるプログラマにCUDAから乗り換えるメリットを訴えられるかがカギを握る。
ただし、1つ忘れてはいけないことがある。PCやデータセンターの「x86」しかり、モバイルの「Arm」しかり、同じプラットフォームでアーキテクチャの「乗り換え」に成功した例はほとんどない、という歴史があるということだ。

関連記事
少年ジャンプ+編集長に聞く「マンガ編集者がAIを使う」可能性 ── 中国には100万人の漫画家志望がいる
(文、撮影・笠原一輝)
笠原一輝:フリーランスのテクニカルライター。CPU、GPU、SoCなどのコンピューティング系の半導体を取材して世界を回っている。PCやスマートフォン、ADAS/自動運転などの半導体を利用したアプリケーションもプラットフォームの観点から見た記事を執筆することが多い
免責事項:
このコンテンツの見解は筆者個人的な見解を示すものに過ぎず、当社の投資アドバイスではありません。当サイトは、記事情報の正確性、完全性、適時性を保証するものではなく、情報の使用または関連コンテンツにより生じた、いかなる損失に対しても責任は負いません。
WikiFXブローカー
話題のニュース
WikiFX「3·15 外国為替権利デー」、ブラックリストを正式に発表
 WikiFX
WikiFXFX投資における悪徳業者リスクの回避~ライセンス規制からリスクを見抜く方法を解説
WikiFXレート計算

